На основе книги An Introduction to Statistical Learning with Applications in R авторов Gareth James, Daniela Witten, Trevor Hastie и Robert Tibshirani. Бесплатная копия книги в PDF-формате, или заказ бумажной копии книги на Amazon.
library(ISLR) library(ggvis) library(dplyr) |
Подготовка данных
Работаем с массивом Auto из пакета ISLR.
# Загружаем массив Auto в пространство пользователя data(Auto) # Структура массива str(Auto) |
## 'data.frame': 392 obs. of 9 variables: ## $ mpg : num 18 15 18 16 17 15 14 14 14 15 ... ## $ cylinders : num 8 8 8 8 8 8 8 8 8 8 ... ## $ displacement: num 307 350 318 304 302 429 454 440 455 390 ... ## $ horsepower : num 130 165 150 150 140 198 220 215 225 190 ... ## $ weight : num 3504 3693 3436 3433 3449 ... ## $ acceleration: num 12 11.5 11 12 10.5 10 9 8.5 10 8.5 ... ## $ year : num 70 70 70 70 70 70 70 70 70 70 ... ## $ origin : num 1 1 1 1 1 1 1 1 1 1 ... ## $ name : Factor w/ 304 levels "amc ambassador brougham",..: 49 36 231 14 161 141 54 223 241 2 ...
# Первые строки массива head(Auto) |
## mpg cylinders displacement horsepower weight acceleration year origin ## 1 18 8 307 130 3504 12.0 70 1 ## 2 15 8 350 165 3693 11.5 70 1 ## 3 18 8 318 150 3436 11.0 70 1 ## 4 16 8 304 150 3433 12.0 70 1 ## 5 17 8 302 140 3449 10.5 70 1 ## 6 15 8 429 198 4341 10.0 70 1 ## name ## 1 chevrolet chevelle malibu ## 2 buick skylark 320 ## 3 plymouth satellite ## 4 amc rebel sst ## 5 ford torino ## 6 ford galaxie 500
# Конвертируем миль (1.609 км) на галлон (3.79 л) в км на литр Auto$kpl <- Auto$mpg * 1.609 / 3.79 |
Построение модели
Построим однофакторную регрессионную модель, чтобы выявлить, как мощность двигателя влияет на пробег на километр топлива, и ответим на следующие вопросы:
- Существует ли взаимосвязь между мощностью и пробегом.
- Насколько сильна взаимосвязь между мощностью и пробегом.
- Взаимосвязь между мощностью и пробегом прямая или обратная.
- Каково прогнозное значение пробега на километр при мощности 98 лошадиных сил. Каковы 95% доверительный интервал и интервал предсказания.
# Задаем модель autolm <- lm(kpl ~ horsepower, data = Auto) # Результаты анализа summary(autolm) |
## ## Call: ## lm(formula = kpl ~ horsepower, data = Auto) ## ## Residuals: ## Min 1Q Median 3Q Max ## -5.761 -1.384 -0.146 1.173 7.185 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 16.95430 0.30461 55.7 <2e-16 *** ## horsepower -0.06701 0.00274 -24.5 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.08 on 390 degrees of freedom ## Multiple R-squared: 0.606, Adjusted R-squared: 0.605 ## F-statistic: 600 on 1 and 390 DF, p-value: <2e-16
Коэффициент horsepower составляет -0.067, т.е. при увеличении мощности автомобиля на одну лошадиную силу пробег снижается на 0.07 км на литр топлива. Наличие этой взаимосвязи подтверждается p-значением t-статистики: t равен -24.5, а вероятность получить такое значение t при независимых переменных (т.е. p-значение) стремится к нулю (<2e-16).
Прогнозирование
# Прогнозируем пробег при мощности 98 л.с. # Доверительный интервал confint <- predict(autolm, newdata = data.frame(horsepower = 98), interval = 'confidence') confint |
## fit lwr upr ## 1 10.39 10.18 10.6
Если мы возьмём несколько разных автомобилей с мощностью двигателя 98 л.с., то средний пробег этих машин на литр топлива с вероятностью 95% попадёт в интервал от 10.2 до 10.6 км.
# Интервал предсказания predint <- predict(autolm, newdata = data.frame(horsepower = 98), interval = 'prediction') predint |
## fit lwr upr ## 1 10.39 6.287 14.49
Если мы возьмём какой-то конкретный автомобиль с мощностью двигателя 98 л.с., то его пробег на литр топлива с вероятностью 95% попадёт в интервал от 6.3 до 14.5 км.
Auto %>% ggvis(~horsepower, ~kpl) %>% layer_points() %>% layer_model_predictions(model = 'lm', se = T) |

Диагностика
После построения регрессионной модели имеет смысл проверить наличие следующих проблем:
- Нелинейная взаимосвязь между независимыми и зависимой переменными.
- Корреляция остатков между собой.
- Непостоянная дисперсия остатков (гетероскедастичность).
- Наличие выбросов.
- Избыточное влияние отдельных наблюдений.
- Коллинеарность предикатов.
par(mfrow = c(2, 3)) plot(autolm, which = 1:6, caption = list("Прогноз и остатки", "Квантили", "Разброс-Положение", "Расстояние Кука", "Влияние и остатки", expression("Влияние и Кук " * h[ii] / (1 - h[ii])))) |
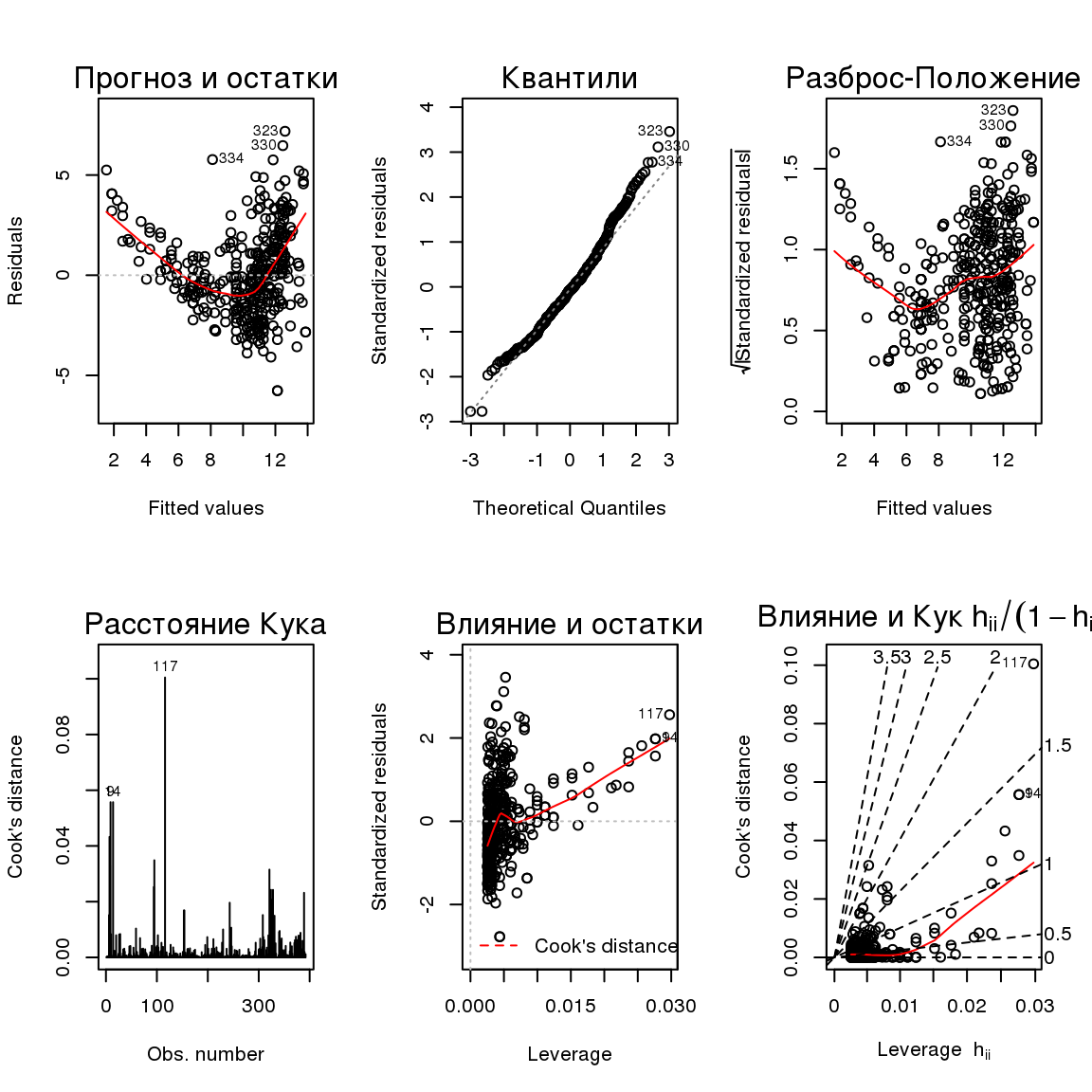
Точечный график предсказанных значений и остатков позволяет обнаружить закономерности распределения последних. График квантилей помогает определить нормальность остатков. График “Разброс-положение” даёт возможность оценить монотонность распределения остатков (гетероскедастичность). С помощью графика “Остатки-влияние” можно определить точки с большим влиянием на модель.
[…] Однофакторный линейный регрессионный анализ в R […]