
Вкратце про онлайн-родословные Несколько месяцев назад я решил выглянуть за пределы своего генеалогического огорода Gramps и расширить подходы к изучению семейной истории с помощью онлайн-сервисов.…
Leave a CommentAuthor: Alexander Matrunich
On the 24th of October 2017, I took part in a seminar by Vincenzo Lagani hosted by the R-Ladies Tbilisi group. Vincenzo gave a broad…
Leave a CommentOnce a colleague of mine told me he had sent out about one thousand resumes to find a suitable job. I was impressed and could…
Leave a CommentThe temporary directory and files Firstly let’s create a folder to work within a temporary directory. Look for details on how to work with temporary…
Leave a CommentWhen temporary files in R become handy Every time you need to download a file from anywhere to extract data from it and then throw…
Leave a Comment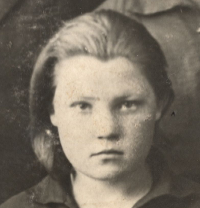
Gramps — это бесплатная компьютерная программа для тех, кто увлекается исследованием истории своей семьи серьёзнее, чем только для для размещения семейного древа в рамке на…
1 CommentThe problem and the opportunity Flows of data in organizations today are constant and unstoppable. A report based on a data slice from a specific…
Leave a CommentEstonian e-residency Estonia has one of the most advanced electronic governments. If not the most advanced. Its citizens can perform legal acts remotely via the…
Leave a CommentПродолжаю тему с однофакторым регрессионным анализом в R. Теперь мне интересно применить инструменты визуализации, доступные в R-библиотеке ggvis, для диагностики регрессионной модели. Здесь же мы…
3 CommentsНа основе книги An Introduction to Statistical Learning with Applications in R авторов Gareth James, Daniela Witten, Trevor Hastie и Robert Tibshirani. Бесплатная копия книги…
1 Comment