Продолжаю тему с однофакторым регрессионным анализом в R. Теперь мне интересно применить инструменты визуализации, доступные в R-библиотеке ggvis, для диагностики регрессионной модели. Здесь же мы применяем перенаправление с помощью функции %>%.
Напомню, что я использую данные, сопровожающие книгу An Introduction to Statistical Learning with Applications in R. Подготовка данных и построение модели было произведено в предыдущей публикации. Так что будем считать, что мы продолжаем творить в пространстве той публикации.
Нелинейность взаимосвязи
data.frame(predict = predict(autolm), resids = residuals(autolm)) %>% ggvis(~predict, ~resids) %>% layer_points() %>% add_axis("x", title = "Предсказанные значения") %>% add_axis("y", title = "Остатки") %>% layer_smooths(stroke := 'red') |
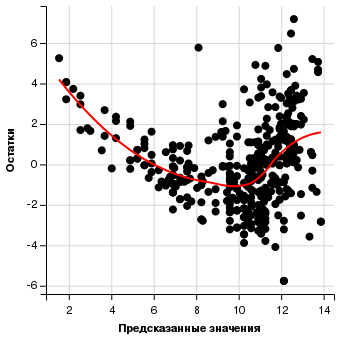
Наблюдается некоторая нелинейная зависимость между остатками и предсказанными значениями. Имеет смысл сделать нелинейное преобразование элементов модели (логарифм, квадратный корень, квадрат).
Корреляция остатков
data.frame(id = seq_len(dim(Auto)[1]), resids = residuals(autolm)) %>% ggvis(~id, ~resids) %>% layer_paths() %>% add_axis("x", title = "Порядковый номер наблюдения") %>% add_axis("y", title = "Остатки") |

График не выглядит таким, что по нему на основе предыдущего наблюдения можно предсказать следующее. Делаем вывод, что корреляции остатков нет.
Непостоянная дисперсия остатков
data.frame(predict = predict(autolm), rstuds = rstudent(autolm)) %>% ggvis(~predict, ~rstuds) %>% layer_points() %>% add_axis("x", title = "Предсказанные значения") %>% add_axis("y", title = "Стьюдентизированные остатки") |

Видно, что с увеличением величины предсказанных значений происходит увеличение разброса остатков: мы наблюдаем изогнутую воронкообразную форму. Это говорит о наличии гетероскедастичности. Отсутствие гетероскедастичности — условие для корректного расчёта стандартной ошибки, доверительных интервалов и тестирования гипотез. В нашем случае можно преобразовать зависимую переменную с помощью какой-нибудь “выгнутой” функции — например, логарифм или корень квадратный.
autolm1 <- update(autolm, log(.) ~ .) data.frame(predict = predict(autolm1), rstuds = rstudent(autolm1)) %>% ggvis(~predict, ~rstuds) %>% layer_points() %>% add_axis("x", title = "Предсказанные значения (log)") %>% add_axis("y", title = "Стьюдентизированные остатки") |

Выбросы
Auto %>% mutate(rstud = ifelse(abs(rstudent(autolm)) > 3, 'Больше 3', 'Не больше 3'), label = row.names(Auto), label = ifelse(rstud == 'Больше 3', label, '')) %>% ggvis(~kpl, ~ horsepower, fill = ~rstud) %>% layer_points() %>% add_axis("x", title = "Километров на литр") %>% add_axis("y", title = "Лошадиных сил") %>% add_legend("fill", title = "Стьюд.остатки") %>% layer_model_predictions(stroke := "red", model = 'lm') %>% layer_text(text := ~label, dy := -5, dx := 5) |
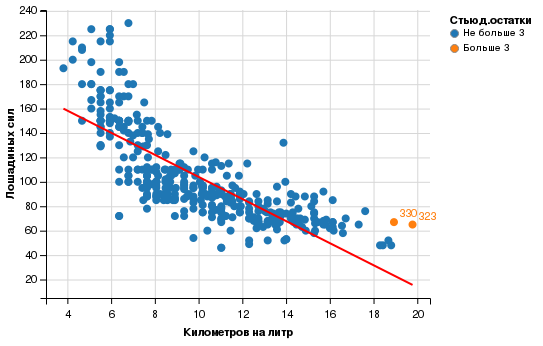
Только у двух наблюдений абсолютная величина стьюдентизированных остатков превышает 3.
Точки с избыточным влиянием на модель (High Leverage Points)
В простой (однофакторной) регрессии мы просто можем посмотреть, какие значения независимой переменной слишком выпадают. Но построим график с оценкой уровня влияния точек.
data.frame(leverage = hatvalues(autolm), rstuds = rstudent(autolm), label = row.names(Auto)) %>% mutate(label = ifelse(leverage > .025, label, '')) %>% ggvis(~leverage, ~rstuds) %>% layer_points() %>% add_axis("x", title = "Leverage") %>% add_axis("y", title = "Стьюдентизированные остатки") %>% layer_text(text := ~label, dy := -5, dx := 5) |

Обогащённая графика с диагностикой модели
data.frame(predict = predict(autolm), resids = residuals(autolm), rstuds = rstudent(autolm), leverage = hatvalues(autolm)) %>% ggvis(~predict, ~resids, fill = ~abs(rstuds), size = ~leverage) %>% layer_points() %>% add_axis("x", title = "Предсказанные значения") %>% add_axis("y", title = "Остатки") %>% add_legend("size", title = "Влияние на модель") %>% add_legend("fill", title = "Модуль стьюд.ост.", properties = legend_props(legend = list(y = 100))) |
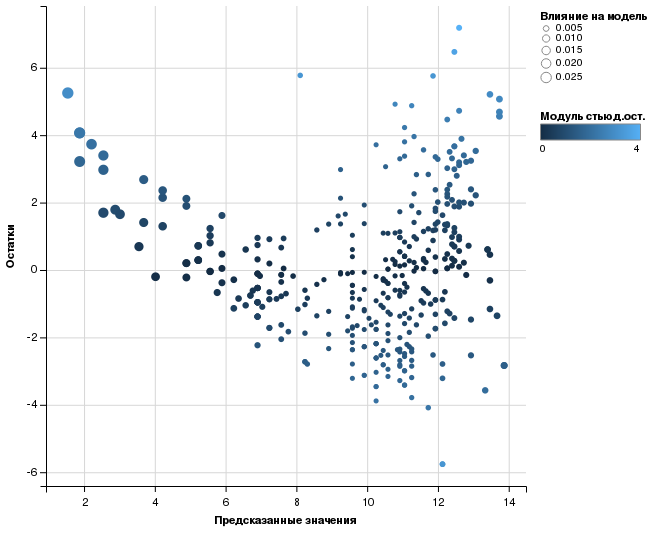
Чем больше точка, тем сильнее её влияние на модель. Чем ярче точка, тем больше у этого наблюдения ошибка предсказания. Закраску точки можно и убрать, поскольку величина остатков коррелирует с величиной стьюдентизированных остатков.
Отчётливо видно, что наблюдения с наибольшим влиянием встречаются в том секторе, где наблюдения встречаются реже.
О, спасибо огромное, утащил в свою копилку.
Вообще (немного оффтопа) – ситуация удручающая: русскоязычных материалов очень мало, особенно по графике и новым возможностям. Сам пытаюсь протащить R в учебную среду, но идет очень со скрипом. А как у Вас?
Поделюсь своими материалами на всякий: http://goo.gl/wQ9rwZ. Кстати, своим я показываю не Joy of Statistics, а Age of Big Data.
Максим, спасибо за ссылку на материалы! RStudio используете? Я правильно понимаю, что кроме английского там другие языки не предполагаются? С кодировкой под виндой у студентов часто проблемы? Я сталкивался и с тем, чтобы пробелов в путях не было.
Пару раз проводил курс по анализу данных с использованием R. Правда, я преподавал у рекламщиков, а не у математиков 🙂 Основной вопрос у меня упирается в мотивацию, а так, вроде бы, народ начинает соображать.
В Высшей школе экономики понемногу, вроде бы, используют. Но тоже большая любовь к пиратским копиям SPSS (“Это ж стандарт!”).
В этом месяце коллега была в Мск на недельных курсах от РАН социологии по анализу данных. Так там некий Воронков (или Воронцов), молодец, заставил всех на синтаксисе всё делать, и народ как будто бы проникся идеей программирования, но всё продолжают преподавать и использовать SPSS. 🙂 Хотя понятно, что по сравнению с R программирование на SPSS выглядит ущербным 🙂
Фильм, вижу, опять от BBC, посвежее и с русским переводом. Спасибо!
Александр, да, RStudio. Другие языки, кроме английского там отсутствуют, это правда. С кодировкой проблем, вроде бы и нет. Единственный баг – при установке рабочего каталога с помощью соответствующего пункта меню и кириллических символов в пути беда с кодировкой в Linux начинается. В Windows вроде всё идет хорошо.
Своих от пиратки отучаю уже пять лет. Тяжеловато, но идёт.
Еще раз спасибо за отличный ресурс.