Сравним речи, которые произнесли руководители России, Белоруссии и Украины 9 мая 2014 года.
Сделаем это с помощью визуализации текстов в виде облака слов.
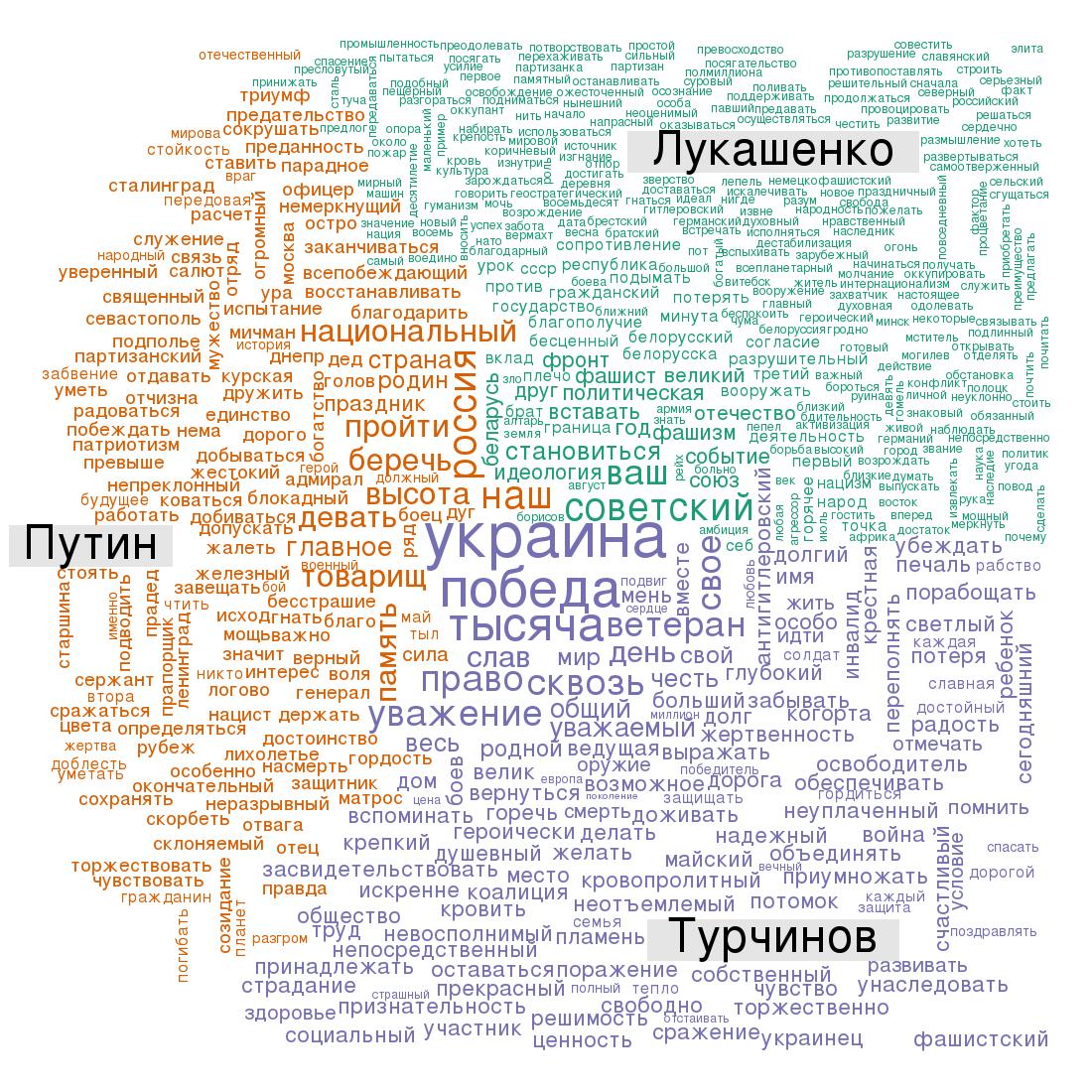
Как интерпретировать график? Размер шрифта, которым изображено слово, показывает относительную частоту, с которой данное слово встречалось в речи. Цвет показывает, в речи какого из президентов данное слово занимает наибольшую долю. Например, слово «победа» (и его формы) встречалось у Лукашенко 5 раз, у Путина – 3, у Турчинова – 5. Понятно, что слово должно попасть или к Лукашенко, или к Турчинову. Но у Лукашенко слово «победа» занимает 0,89% от массива учтённых слов, а у Турчинова – 2,8%, соответственно оно попадает в украинскую часть графика.
У Лукашенко много слов с маленьким размеров шрифта – это значит, что он говорил больше, чем остальные спикеры, размер словаря его выступления больше, и на каждое слово у белорусского президента приходится меньшая относительная частота. Действительно, у Лукашенко зафиксировано 562 слова, у Путина – 229, у Турчинова – 177.
Чем схожи выступления спикеров? Это можно проверить с помощью облака сходства. Здесь приведены слова, которые встречались одновременно у всех трёх выступающих. Чем больше размер шрифта, тем выше средняя доля встречаемости слова.

При подготовке из текстов выступлений были удалены стоп-слова (предлоги и пр.), а оставшиеся слова были приведены к исходной словоформе с помощью программы MyStem от компании Яндекс. Поскольку определение первичной словоформы происходит в автоматическом режиме без учёта контекста, некоторые слова преобразованы некорректно. Например, слово «дуг» в речи Путина в оригинале звучало как «Дуге». Обработка данных произведена в среде статистической обработки данных R. Более подробно о создании графиков в виде облака слов можно ознакомиться в публикации Обработка естественно-языковых текстов в R: облако слов.
Источники информации
- Турчинов поздравил украинцев с Днем Победы: полный текст обращения. Информационное Агентство 112.ua
- Владимир Путин присутствовал на военном параде в ознаменование 69‑й годовщины Победы в Великой Отечественной войне. Администрация Президента РФ
- Выступление Президента Республики Беларусь А.Г.Лукашенко на церемонии возложения венков к монументу Победы. Пресс-служба Президента Республики Беларусь